

在近期与诺本集团联合举办的以IT运维为主题的研讨会上,Splunk资深售前工程师徐世文先生从三个方向论述了数字化转型对IT运维提出的要求,今天我们整理出来,以飨读者。

过去几年,尤其是疫情爆发以来的最近两年,IT环境发生了天翻地覆的变化,数字化转型速度达到前所未有的高度。越来越多的组织开始创建并依赖数字化服务,越来越多的应用被开发、测试、发布以及部署。为了适应这一变化企业需要对其应用进行重构,为了让这些应用在容器和云上更好运行,松耦合微服务架构以及模块化设计正逐步被企业采用。
这种转变在为企业带来收益的同时,也给企业环境带来了较大的复杂性。具体来说,一个应用由前端和后端构成,前端与后端之间本身就有着复杂的相互依赖的关系,在如今微服务的架构之下,后端存在的数十个或数百个松散耦合的不同语言的服务,本就相当复杂,而前端所承担的功能已不再局限于页面加载,还有一部分安全和业务逻辑的功能。
另外一个原因,向云迁移带来的一大特点,便是基础设施呈动态发展,直接导致监控指标和数量的大幅增加和快速发展。在此情况下,传统的点监控IT运维的工序放大了复杂性。对于ITOps人员来说,太多环境意味着需要更多工具提供支持,需要更强大的专业知识进行应对,需要在更多的数据源中进行定位,在这种环境下,MTTR普遍较长,而灵活性也大打折扣。
所有复杂因素和驱动因素都在增加着对ITOps的需求,而更好的管理和技术也带来了数据的指数级增长,这种增长进一步强化了对数据处理性能的要求。对于ITOps团队来讲,他们需要一种全新的工具能够帮助他们适应这种增长。
有矛必有盾。要实现如此复杂环境下的IT运维,我们必须跳出思维窠臼,从传统监控转向可观察性上。
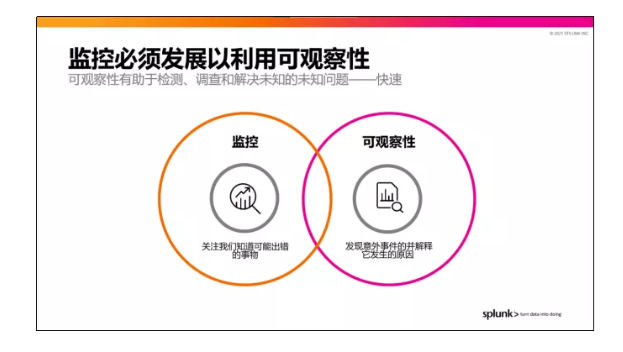
那么监控与可观察性之间有何区别呢?徐世文举了一个生动的例子,“两者最大的区别在于监控专注于那些我们已经摸清楚规律的问题:我有一台服务器,CPU温度超过90度后这台服务器就会不稳定,我们针对这台服务器的温度做一个监控,当它超过90度时就会发出告警,这便是典型的监控案例;而在可观察性方面,我会拿到这个服务器上面我能够拿到的所有数据,不光是CPU 温度,还有可能是网络流量、硬盘型号、已经部署的应用的数量、它的内存以及上面各式各样的数据。当某一天我发现这台服务器宕机或者性能偏低的时候,我就可以借助收集到的所有数据来找到它内在的规律和联系,通过包括时间在内的各种维度来定位错误和意外,用数据来找到它的规律,找到它内在的联系,通过包括时间在内不同维度,找到错误和意外,用数据去解释错误和意外,这就是用可观察性方法来解决问题的原则。”
某种意义上说,只要你的系统可观察性足够高,当系统出现故障时,就能够方便快捷地实现根源定位,从而第一时间解决问题。
那么,可观察性是如何帮助我们解决问题的呢?
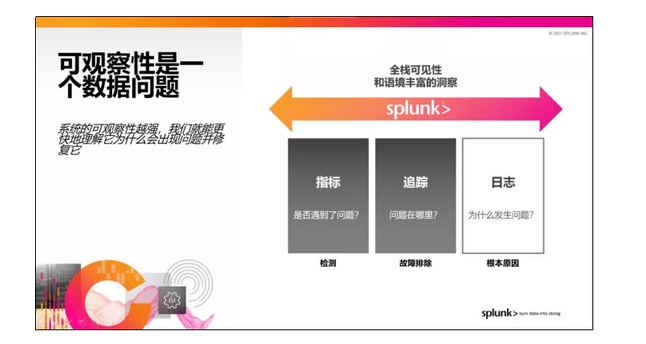
可观察性是通过三大数据要素来帮助我们解决问题的:指标、追踪、日志。在这里,指标回答的是系统是否遇到了问题,追踪帮助我们了解问题出在哪里,而日志则提供了最详细的信息,帮助我们发掘根因。这三大数据要素为我们提供了整个系统以及整个应用全栈的可见性,帮助我们理解复杂系统行为以及未知的故障条件。
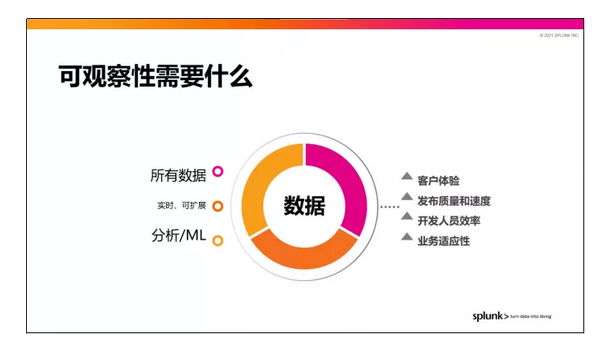
好的可观察性解决方案对数据要求颇高:
第一点:数据要全。我们用完全报检和非采样的方式收集和测量有关环境里的全部数据,这是我们排除故障的基础。
第二点:数据要快。进入系统的必须是刚刚产生的数据,只有这样我们才会拥有真正意义上的数据引擎,能够随着数据的进入完成对整个过程数据流的处理,并且实时告警。
第三点:要有智能。我们有了足够快的数据,能对其进行足够快的处理,这时我们就需要建立起强大的机器学习模型,自动完成原本需要大量人力物力才能处理的排障过程。
只有具备以上三项能力,ITOps团队才能推动业务成长、改善用户体验、提高开发团队的发布质量和速度并最终影响业务适应性。
总体而言,Splunk可观察性解决方案可帮助客户获得远比监控这种旧的方式更强大的可见性。
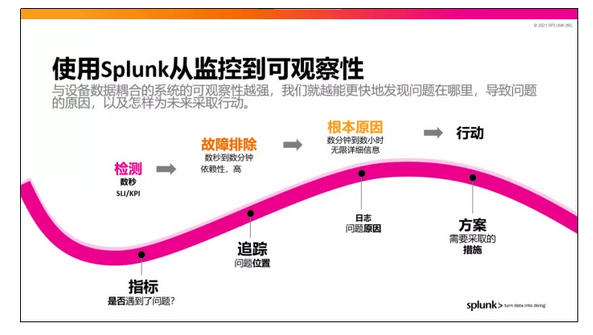
与其他厂商不同,Splunk并非通过多个产品来提供不同类型的服务,而是提供一整套完整的可观察性解决方案,其中包含最优的指标,最优的追踪日志的信息,以及全栈端到端的可见性,帮助客户了解应用性能、使用情况以及使用瓶颈。
在Splunk可观察性解决方案的加持下,无论系统中出现什么问题,客户都能通过检测、分类、分析,最终实现对这些未知问题的解决。
举例来说,在业务转型不断加速的当下,容器技术的采用为监控提出了挑战,而随着向云迁移进程的不断深入,云原生在提升速度的同时也大大增加了复杂性。对于那些部署在Kubernetes 容器中,运行在云上的应用程序,我们如何去监控呢?
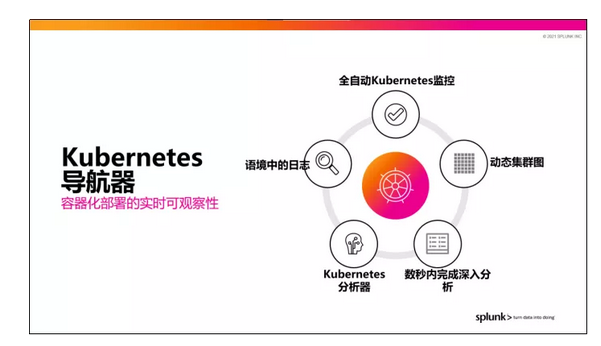
Splunk Kubernetes导航器,可助力客户实现全自动Kubernetes监控,可对动态集群图里上百甚至上千个Kubernetes Pod的健康状况进行实时观察。如果有一些Pod呈现红色或黄色的非健康颜色,客户可以通过点击在几秒之内完成深入分析,找到其中对应的错误日志,然后在同一个环境中找到和这个Pod相关的所有应用程序,并结合网络情况和相关日志进行联合查询,最终找到Pod产生错误的原因。

Splunk基础设施监控,作为一个实时流指标的平台允许客户针对本地甚至是多云环境进行监控。客户可以连到本地的Windows,也可以连到机房的Linux,甚至AWS, Google Cloud, Azure等公有云平台,然后通过自动服务发现的方式一站式获得基础设施健康状况。

在基础设施和故障排除方面,Splunk ITSI,即业务服务智能和事件分析,能够让Splunk从监控一开始就能通过深度链接导航到产生问题的具体数据,然后通过SPL搜索、ITSI力矩、仪表板等方式进行排障工作。这些工具可以帮助ITOps团队在正确的时间从正确的系统获取正确的数据,从而实现问题的更快解决。
另外,Splunk ITSI还提供了大量与IT运维相关的内容包,其中包含了非常多的预配置相关搜索,用于从每个集成服务器的环境中间提取Splunk基础设施监控的事件数据,然后把这些异常事件插入ITSI里面进行事件处理。
不仅是对基础设施的监控,Splunk还可实现统一全IT领域的监控。以上云这件事来说,原来孤岛式的工具无法在多个云中间联合起来做查询,使用Splunk后,客户可在多个云上自动获取其发布的数据并填充仪表板,实现可视化。此外,客户还可以借助统一工具验证向云迁移是否成功,同时使用统一界面打破运行孤岛、简化工作流程,实现DevOps, ITOps以及业务等不同团队间的无缝协作。

总体而言, Splunk可满足多云监控管理的需求,通过统一界面显示任意来源的数据,为客户提供可见性,助其了解到应用在环境中的部署和运行状况。通过Splunk统一的工具,助力客户打破工具孤岛,专注业务结果。同时,Splunk解决方案支持客户所面对的当前以及未来的需求,助其最大限度利用技术投资,满足企业未来对于IT运维的需求。

专业的团队服务

丰富的解决方案

众多的行业案例

广泛的服务区域

深入的厂商合作
Copyright © 2021 Binqsoft 上海隐石信息科技发展有限公司
沪ICP备16031315号-2 |
 沪公网安备 31010402004956号
沪公网安备 31010402004956号